OneSchema is a capable data importer, and if you're reading this, you've probably already built something on it. Maybe the pricing scaled faster than expected. Maybe you hit a wall trying to customize the mapping UI. Maybe AI column mapping was on the roadmap but never arrived. Whatever the reason, this post walks through the concrete steps to migrate from OneSchema to Xlork — with working code for both the React and Node.js paths.
This is not a sales pitch disguised as a migration guide. You'll see real code on both sides, a feature-by-feature comparison, and an honest assessment of where the differences actually matter for your use case.
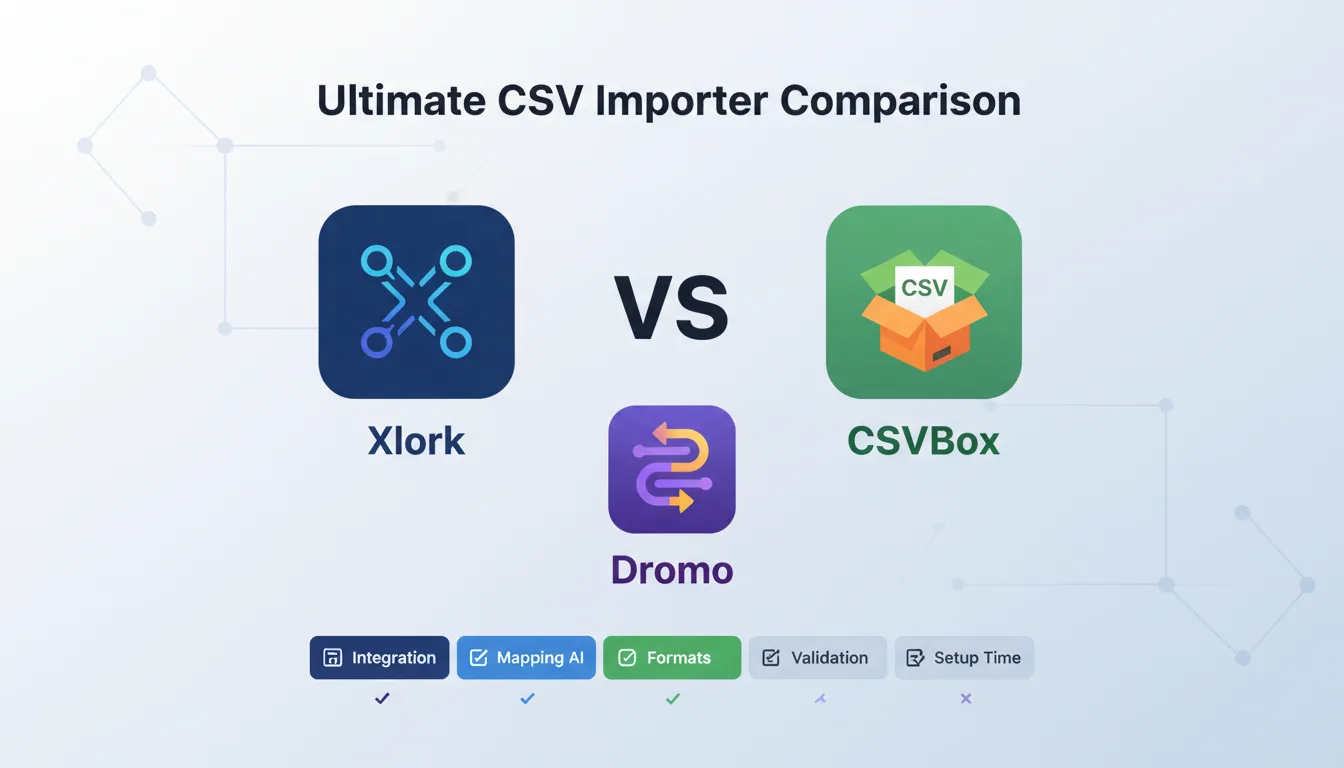
1OneSchema vs Xlork: Where They Differ
Both tools solve the same core problem: give your users a UI for uploading structured data files, validate the data against your schema, and deliver clean rows to your application. The divergence is in how they approach AI mapping, SDK design, pricing structure, and client-side data handling.
- ✓AI column mapping: Xlork uses multilingual embedding-based semantic matching that works on unseen column names at inference time. OneSchema uses template-based matching with configurable synonyms — effective for known patterns, but requires manual updates for new source formats.
- ✓SDK design: Xlork ships separate React and Node.js SDKs with TypeScript definitions included. OneSchema ships a React SDK; server-side integration uses the REST API directly.
- ✓Pricing: Xlork publishes pricing on the website — $0 (free tier), $9, $29, and $49/month. OneSchema requires contacting sales for pricing, which adds friction for teams evaluating options.
- ✓Data privacy: Xlork runs column mapping inference client-side via WASM — uploaded file contents do not leave the browser during the mapping step. OneSchema processes data server-side.
- ✓Format support: Both support CSV and Excel. Xlork additionally supports XML, JSON, TSV, and Google Sheets URL imports natively.
- ✓Customization: Both expose theme configuration for colors and typography. Xlork exposes the full import lifecycle via callback hooks, allowing transformation logic at each step.
💡 Pro tip
If your primary concern is AI column mapping quality on messy, real-world spreadsheet exports from Salesforce, HubSpot, or hand-maintained sheets in languages other than English, run a parallel test before committing to the migration. Paste the same file into both tools and compare auto-mapping accuracy on your actual data.
2Feature Comparison Table
- ✓React SDK: Both — OneSchema (yes), Xlork (yes)
- ✓Node.js SDK: OneSchema (REST API only), Xlork (dedicated SDK with TypeScript types)
- ✓AI column mapping: OneSchema (template + synonym rules), Xlork (embedding-based semantic similarity)
- ✓Multilingual column headers: OneSchema (manual synonym config), Xlork (built-in via multilingual embeddings)
- ✓Client-side data processing: OneSchema (no — server-side), Xlork (yes — WASM in-browser)
- ✓CSV / TSV / Excel: Both (yes)
- ✓XML / JSON import: OneSchema (no), Xlork (yes)
- ✓Google Sheets URL import: OneSchema (no), Xlork (yes)
- ✓Published pricing: OneSchema (contact sales), Xlork (public — from $0/month)
- ✓Free tier: OneSchema (trial only), Xlork (yes — up to 100 imports/month)
- ✓Webhook support: Both (yes)
- ✓Custom validation hooks: Both (yes)
3Migrating the React Integration
OneSchema's React component uses a session-token model. Your backend creates an import session via the OneSchema API, returns a JWT to the client, and the frontend renders the importer using that token. Here's a representative OneSchema setup:
// OneSchema React integration (before migration)
import OneSchemaImporter from '@oneschema/react';
function ImportButton() {
const [open, setOpen] = useState(false);
const [sessionToken, setSessionToken] = useState<string | null>(null);
async function handleOpen() {
const res = await fetch('/api/oneschema/session', { method: 'POST' });
const { token } = await res.json();
setSessionToken(token);
setOpen(true);
}
return (
<>
<button onClick={handleOpen}>Import Data</button>
{sessionToken && (
<OneSchemaImporter
isOpen={open}
clientId={process.env.NEXT_PUBLIC_ONESCHEMA_CLIENT_ID!}
userJwt={sessionToken}
templateKey="contacts"
onSuccess={(data) => console.log(data)}
onCancel={() => setOpen(false)}
/>
)}
</>
);
}The Xlork React equivalent does not require a backend session creation step. Your API key and schema live in the Xlork dashboard and are referenced by an importer ID. The React component is initialized with that ID directly.
// Xlork React integration (after migration)
import { XlorkImporter } from '@xlork/react';
function ImportButton() {
const [open, setOpen] = useState(false);
return (
<>
<button onClick={() => setOpen(true)}>Import Data</button>
<XlorkImporter
importerId={process.env.NEXT_PUBLIC_XLORK_IMPORTER_ID!}
open={open}
onComplete={(result) => {
console.log(`${result.rows.length} rows imported`);
setOpen(false);
}}
onClose={() => setOpen(false)}
/>
</>
);
}The migration removes the backend session endpoint entirely. You no longer need a server round-trip before the importer opens. The trade-off is that schema changes happen in the Xlork dashboard rather than in code — which most teams find acceptable, and some prefer.
4Migrating the Schema Definition
OneSchema manages templates (schemas) through the OneSchema dashboard UI. Each template defines columns with types, required flags, and validation rules. Xlork offers the same through its dashboard, plus the option to define schemas programmatically via the Node.js SDK.
A OneSchema template column that looks like this in the API:
{
"key": "email",
"label": "Email Address",
"data_type": "EMAIL",
"is_required": true,
"description": "Primary contact email",
"validation_options": {
"allow_duplicates": false
}
}Translates to this in Xlork's schema format:
import type { XlorkField } from '@xlork/node';
const emailField: XlorkField = {
key: 'email',
label: 'Email Address',
type: 'string',
required: true,
description: 'Primary contact email',
validators: [
{ validate: 'email' },
{ validate: 'unique' },
],
};💡 Pro tip
Xlork's validator types include: email, url, regex, unique, length_min, length_max, number_min, number_max, and date. For custom logic not covered by built-in validators, use the transform hook to run arbitrary TypeScript before data reaches your database.
5Migrating the Webhook Handler
OneSchema fires a webhook to your configured endpoint when an import session completes. The payload contains the template key, session ID, and the cleaned rows as a JSON array. Signature verification uses HMAC-SHA256.
Xlork uses the same pattern. The payload structure is slightly different, but the verification logic is identical in concept:
import { XlorkClient } from '@xlork/node';
import type { Request, Response } from 'express';
const xlork = new XlorkClient({ apiKey: process.env.XLORK_API_KEY! });
export async function xlorkWebhookHandler(req: Request, res: Response) {
const signature = req.headers['x-xlork-signature'] as string;
const isValid = xlork.webhooks.verify({
payload: JSON.stringify(req.body),
signature,
secret: process.env.XLORK_WEBHOOK_SECRET!,
});
if (!isValid) {
return res.status(401).json({ error: 'Invalid signature' });
}
// Acknowledge immediately before processing
res.status(200).json({ received: true });
const { rows, metadata } = req.body;
// rows: ValidatedRow[] — same structure as OneSchema's 'data' array
await processImportedRows(rows, metadata.importerId);
}The key difference from OneSchema is the `metadata.importerId` instead of `template_key`. Update your routing logic if you use the template key to determine which processing function to invoke.
6Handling the OneSchema onSuccess Callback
Some teams use OneSchema's client-side `onSuccess` callback to receive data directly in the browser and send it to their own backend endpoint, bypassing webhooks entirely. Xlork supports the same pattern via the `onComplete` callback:
// Send data from the browser to your own API endpoint
<XlorkImporter
importerId={process.env.NEXT_PUBLIC_XLORK_IMPORTER_ID!}
open={open}
onComplete={async (result) => {
await fetch('/api/import/contacts', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ rows: result.rows }),
});
setOpen(false);
}}
onClose={() => setOpen(false)}
/>7Migration Checklist
- ✓Install @xlork/react and @xlork/node, remove @oneschema/react from package.json
- ✓Create an importer in the Xlork dashboard and replicate your OneSchema template columns as Xlork fields
- ✓Replace the OneSchemaImporter component with XlorkImporter, remove the session token backend endpoint
- ✓Update environment variables: replace ONESCHEMA_CLIENT_ID and ONESCHEMA_SECRET with XLORK_API_KEY, NEXT_PUBLIC_XLORK_IMPORTER_ID, and XLORK_WEBHOOK_SECRET
- ✓Update webhook endpoint: change signature verification to use xlork.webhooks.verify(), update payload field references from OneSchema's structure to Xlork's
- ✓Test with your most common source file formats — Salesforce exports, HubSpot exports, custom spreadsheets
- ✓Verify AI column mapping accuracy on your schema against real user files
- ✓Update your error reporting logic if you were using OneSchema's column-level error format
8What You Get After the Migration
The immediate practical changes: you eliminate the backend session creation round-trip, gain XML and JSON import support, and your users get AI column mapping that works on multilingual and previously unseen column name patterns without requiring synonym configuration. File data that was previously processed server-side on OneSchema's infrastructure now processes in the browser via WASM.
If you were on OneSchema's entry-level plan and your usage fits the Xlork free tier (up to 100 imports per month), the migration also reduces your monthly cost to zero for the same capability set.
The migration effort is a few hours of engineering time — replacing one SDK with another and updating a webhook handler. The schema definition work is a one-time cost regardless of which tool you use.
💡 Pro tip
Start the migration with the Xlork free tier at xlork.com. You can run Xlork in parallel with your existing OneSchema integration during the transition period to validate behavior before switching over completely.